COLUMNコラム
模倣を抑止するインフォメーションゲイン(情報利得)とは? スコアを高める方法も解説
SEOにおいて上位コンテンツの模倣は決して間違いではありません。むしろ「現在の検索意図に応える」「網羅性を確保する」手法として、今なお有効です。しかし、近年ではそれだけでは評価を獲得できなくなってきました。検索意図・網羅性を満たした上で、独自性のある情報を提供しなくては検索上位に食い込めなくなっています。
この独自性を評価するロジックとして検索エンジンに組み込まれていると考えられるのが、インフォーメーションゲイン(情報利得)です。Googleは2018年に、この情報利得に関連した特許を出願し、2022年6月に特許を取得しています。当時のSEO界隈では「Googleが検索エンジンの評価基準をシフトさせる動きを見せた」と話題になりました。公式からの明言こそなかったものの、これ以降、アップデートを通じて独自性を持つコンテンツが評価される傾向が強まっています。
この記事では、インフォーメーションゲイン(情報利得)を通じてGoogleが求める独自性の曖昧さをクリアにしていきます。コンテンツ作成やSEO対策の根幹に関わる内容です。サイト制作に関わる方はぜひご覧ください。
インフォメーションゲイン(情報利得)とは

インフォーメーションゲイン(情報利得)とは、変換前と変換後のデータセットのエントロピー(不確実さ)を比較したもので、機械学習の分野における決定木分析のトレーニングによく使用されています。
決定木分析とは、データを複数の質問で段階的に分割し、最終的な分類や予測の結果を導き出すフローチャートです。
たとえば、決定木分析で週末に観る映画を選ぶと次の図のようになります。
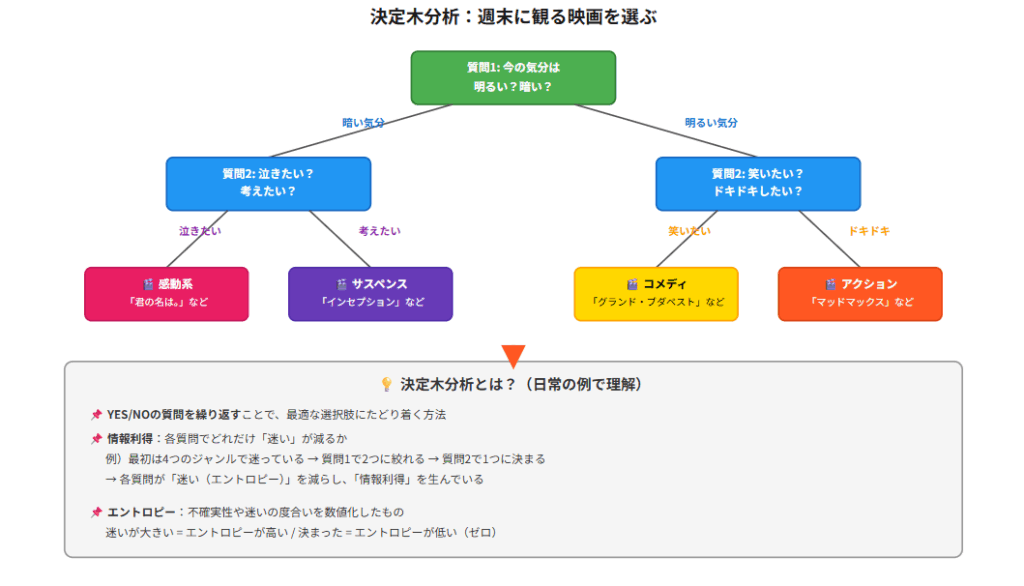
質問を重ねるごとに最終的な選択肢の純度が高まり、エントロピー(迷い)が減少していきます。この減少量が、情報利得です。SEO視点では「提供する情報がユーザーのエントロピー(疑問や問題)を、他ページと比較してどれだけ効率的に解消できるか」を測る指標として用いられます。
情報利得は、概念としては1940年代から存在していたものの、これまで、SEO界隈では積極的に取り上げられるテーマではありませんでした。しかし、2018年代になってGoogleが情報利得に関連した特許を出願したことで、状況に変化が訪れています。
SEO界隈で注目を集めた背景
Googleは2018年にContextual estimation of link information gain(リンク情報利得の文脈推定)という特許を出願しています。
特許タイトル:リンク情報利得の文脈推定
公開番号: WO2020081082A1
国際出願日:2018年10月18日
国際出願番号:PCT/US2018/056483
公開日:2020年4月23日
特許取得:2022年6月
申請者: GOOGLE LLC
発明者: Victor Carbune, Pedro Gonnet Anders
この特許内容が2020年に公開されると、SEO界隈でインフォメーションゲイン(情報利得)への注目が高まりました。以下はGoogle Patents(Googleの特許検索サービス)の概要説明を和訳した文章です。
本明細書では、ユーザにとって関心のある1つ以上の文書の情報利得スコアを決定し、その情報利得スコアに基づいて文書から情報を提示する技術について説明する。ある文書の情報利得スコアは、ユーザが以前に閲覧した文書に含まれる情報に加えて、その文書に含まれる追加情報を示す。いくつかの実施形態では、1つ以上の文書の情報利得スコアは、文書からのデータを機械学習モデルに適用して情報利得スコアを生成することによって決定することができる。文書セットの情報利得スコアに基づいて、ユーザが文書を閲覧した場合に得られる可能性のある情報利得を反映する方法で、文書をユーザに提供することができる。
参照:Google Patents(Googleの特許検索サービス)
概要を見た当時のSEO関係者は「情報利得スコアに基づいて文書から情報を提示する」という文から、Web検索エンジンのランキング要因に「情報利得」という要素が加わると推測しています。
そして、その情報利得スコアは「ユーザが以前に閲覧した文書に含まれる情報に加えて、その文書に含まれる追加情報を示す」という文から、独自性のあるコンテンツを有利にするランキング要因と結論付けました。
この文を更に明快にすると次の通りです。
- 「ユーザが以前に閲覧した文書」= 既にネット上に存在している「既存情報(文脈)」
- 「追加情報」= 既存情報(文脈)の中に含まれる新規情報
つまり、情報利得スコアを「コンテンツに含まれる新規情報の割合」と解釈したのです。この推測は、コンテンツの価値が「量やキーワード」から「独自性」にシフトしつつある証拠とされ、SEO関係者の間で話題になりました。
検索エンジンに組み込まれているのは「ほぼ確実」
Googleはこの特許技術が検索エンジンに組み込まれているかを明らかにはしていません。しかし、状況から察するにほぼ確実でしょう。
大きな根拠として挙げられるのが特許取得から2か月後の2022年8月に実施されたヘルプフルコンテンツアップデートです。このアップデートでは「低品質なコンテンツ」の定義が見直され、それを自動的に識別してランキングから排除するアルゴリズムが導入されました。
Googleは公式に発信した情報ページ「2022年8月のGoogleの有用なコンテンツの更新についてクリエイターが知っておくべきこと」の中で、低品質と見なされるコンテンツの特徴を自己診断形式で明確にしています。その8つの質問のうち、次の3つが情報利得スコアに大きく関わる内容です。
①主に他の人の意見を要約しているか
②ユーザーが再び検索する必要があると感じさせるか
③実際の経験がないのにニッチなトピックを扱っているか
これらの質問に「はい」と答えると情報利得スコアを満たせないコンテンツということになります。①は既存情報の焼き直し、②は情報利得の不足、③は実体験が伴わないので結果的に①と②に陥るからです。
実際にヘルプフルコンテンツアップデート以降、情報利得スコアの影響を思われる順位変動が起こっています。新規情報の無いサイトは順位を落とし、代わりに独自データや専門家による一次情報を提供しているサイトが上位表示されるようになりました。
Googleの狙いは模倣サイトの抑制
この結果はGoogleの狙い通りだったといわれています。新規情報の無いサイト = 模倣サイトが抑制されることで、Web全体の情報利得が高まったからです。
情報利得の解説を読んだ方の中には「内容を模倣しても情報利得を高められるのでは?」と疑問に思った方もいらっしゃるでしょう。確かにその通りです。既存であっても情報を網羅的に揃え、分かりやすく要約できれば、「探索の手間」という不確実さ(エントロピー)を減少させる形で情報利得を高められます。
しかし、それはあくまでユーザー個人での視点です。Web全体で見れば、模倣サイトが高く評価されてしまう仕組みには、やはり欠陥があります。
Googleが特に懸念したのは検索結果の単調化です。模倣で評価が得られる状況では、制作側は新しい情報を集めてコンテンツを作る動機を失い、扱うテーマも既存でメジャーなものに集中します。こうなると、検索上位には似たような内容のサイトが並び、情報の独自性や多様性が薄れていきます。結果、ユーザーが新しい知見を得たり、ニッチな課題を解決したりするのが難しくなります。
このような状態に陥ることが、Web全体といった大きな規模で情報利得を損ねるのは間違いありません。Googleの狙いが模倣サイトの抑制だった、というのは理に適った推測です。
情報利得スコアをSEOで活用するには、マクロな視点で見る必要があります。記事単位ではなく「Web全体にどの程度の新しい価値を提供できるか」を重視しましょう。
情報利得スコアによるSEOの変化

情報利得スコアの存在がほぼ確実視されるようになってから、コンテンツの評価基準が明らかに変わりました。それに伴い、従来のWeb対策は通用しなくなり、SEOも方向転換を余儀なくされています。ここでは、情報利得スコアが引き起こしたSEOの変化について解説します。
模倣戦略の終焉
情報利得がランキング要因として注目されるようになり、従来効率的だった「上位サイトを模倣・改善して順位を上げる」という戦略が通用しなくなりました。より具体的には「検索意図や網羅性を満たしていても、独自情報を提供できなければ評価されにくい構造」へと変化しています。
■ 情報利得スコアなし
上位サイトを分析し検索意図と網羅性を満たすだけで上位表示が可能
→ 模倣サイトの制作が効率的だった
■ 情報利得スコアあり
検索意図・網羅性を満たした上で独自情報を提示しなければ評価されない
→ 情報利得を意識したコンテンツ制作が必須に
例として、商品のレビューサイトにおける順位変動の傾向を見てみましょう。
下落したタイプ
- Amazonレビューをまとめて要約しただけ
- 他サイトのスペック表を寄せ集めただけ
- 「おすすめ○選」で商品を実際に使っていない
上昇したタイプ
- 実際に商品を購入し、計測データを掲載
- 自前の写真や検証過程を提示
- 他サイトにない観点で比較(耐久性・温度変化などの検証)
このように、情報利得スコアが注目され始めた時期から「少量でも独自性のある記事 > 大量の模倣記事」という評価軸がSEOの主流となりました。
人間の注力すべき領域が明確化
模倣サイトの評価が下がることで、SEOで人間が注力すべき仕事も明確化しています。
特に近年ではAIの発展が目覚ましいです。一般的な説明やよくある情報のまとめといった既存コンテンツの模倣が伴う制作工程は、AIを活用した方が効率的にこなせるようになっています。
そのため、SEO達成のためには、AIには頼れない情報利得の高い仕事を人間に割り振る効率性が求められます。具体的には次のような工程があるでしょう。
- オリジナル調査・データ
- 専門家へのインタビュー
- 実体験に基づく知見
- 独自の視点や分析
これらはAIには作れない競争優位性です。これからのSEOは、人間が生み出す独自情報をどれだけ丁寧に積み上げられるかがカギになるでしょう。
情報利得スコアを高める6つの方法

SEOでは模倣の価値が低下し、独自情報の提示が必須になりつつあります。どうすれば、独自性を満たしたコンテンツを作成できるでしょうか? 最後に情報利得スコアを高める6つの方法を解説します。
エンティティを活用して関連性を強調する
エンティティとは、「実体」や「存在」という意味です。このエンティティを活用することで「このページは他と違う情報を提供している」と示し、情報利得を高められます。
たとえば、同じ野球シューズを紹介する記事でも、単に「人気の野球シューズ」と書くのと、「大谷翔平が2024年シーズンに実際に使用した野球シューズ」と具体的に書くのでは、情報利得に差が出ます。これは、私たちが「大谷翔平」を世界で活躍する有名な選手だと知っているからです。検索エンジンもWeb上の情報から「大谷翔平」という語に「世界的な野球選手」という実体(エンティティ)が紐づいていると理解します。
このような具体的なエンティティを含めることで、検索エンジンはそのページが「野球」ジャンルで高い関連性や独自性を持つと判断しやすくなります。Googleが認識する主なエンティティは次の通りです。
人物:選手名、専門家名、著名人
製品名:具体的なモデル名、ブランド
地名:特定の施設、球場、地域
日付:発売日、シーズン、イベント
数値:具体的なスペック、価格、データ
キーワードのエンティティを把握して適切に含めることで、ページの関連性と独自性から情報利得を高められます
情報利得で重要なのは「ユーザーがまだ得られていない情報を提供すること」です。そこで、上位サイトを調査して、コンテンツに付け足せる「抜け情報」がないか探します。抜け落ちている情報は、ユーザーの不満点になるため、そこを埋める行為自体がユーザー満足度の向上に直結します。
競合が扱っていない「抜け情報」を埋める
たとえば「ふるさと納税 控除上限」の記事で、上位の競合記事が計算方法しか書いていなかったとします。しかし、ユーザーの中には、もっと正確に上限額を知りたい、計算が苦手といった人もいるでしょう。それを考慮し「控除上限額に影響する要素」や「計算に便利なツールの紹介・使い方」といったトピックを提供します。
分析が適切であれば、提供する情報がユーザーのエントロピー(疑問や問題)を効率的に解消できます。網羅性の向上によって、情報利得を高めることが可能です。
独自情報により新規価値を提供する
独自情報はユーザーにとって「ここでしか得られない知識」です。他に存在しない一次情報は、新しい価値を作りだします。Web全体の情報利得を高めるため、検索エンジンは独自情報を高く評価します。
実際に、検索上位では独自情報を多く含んだサイトは長期間順位を保つのに対し、少ないサイトは下落しやすい傾向があります。これは、検索エンジンが一次情報提供者を記録し、持続的に評価するアルゴリズムを複数備えているため、と考えられています。
独自情報を作り出す方法としては、自己体験をベースにしたコンテンツ作成があります。たとえば、「副業の稼ぎ方」というテーマなら、自分が実際に月5万円を稼ぐまでのエピソードや収益データを掲載します。このようなコンテンツは、テーマ自体がありきたりであっても「自分の環境での再現性」という独自の視点を提供できるため、読者に高く評価されます。検索エンジンも「再現性のある一次情報」として、単なる再構成記事より高く評価します。
独自情報は、情報利得を高める正攻法です。持続的かつ強力なSEO資産にもなります。
専門家の知見を取り入れて信頼性を高める
情報利得は「正確性」や「信頼性」を含んだ概念です。これらが確保されていなければ、たとえ独自情報であっても評価されることはありません。そのため、根拠となる専門家のコメントや監修は非常に重要です。
特にYMYL領域では、専門家の関与は検索順位に直結します。誤情報が健康、経済、安全、幸福に悪影響を与えると判断されたジャンルについては、記事内容が高品質であっても専門性・信頼性がなければ上位表示されないようになっています。
たとえば「効率的なダイエット方法」などを健康に関連したテーマなら、医師や専門家の監修を受けていることを明記します。専門性の表記が「正確性」や「信頼性」の保証になり、読者への安心感と説得力を飛躍的に高めます。
YMYL領域に限らず、「正確性」や「信頼性」の確保の必要性は、年々拡大傾向です。情報利得を高める前提として専門家の知見を取り入れましょう。
ユーザーの悩み・質問に答える
検索エンジンは「検索意図への理解度」に基づいてページを評価します。そのため、SEOでは、ユーザーの悩みを特定して答えられるほど有利になります。
たとえば「クレカ 審査 通らない」というクエリでは、ユーザーは「なぜ落ちたのか」を知りたいと考えていると推測できます。これを具体化すると、ユーザーは次のような疑問を抱いているはずです。
「どんな理由で落ちる?」
「落ちたらどれくらい期間を空けるべき?」
「今できる対策は?」
悩みを具体化できたら、それを解決するトピックを考えます。この場合、次のようなトピックが該当するでしょう。
「属性別(学生・フリーランス・転職直後)で落ちる典型理由」
「審査に通りやすいカードの比較」
「落ちた後にやるべき具体的なステップ」
一般的な審査基準なら他サイトでも扱っています。他記事では得られない実践的な回答を用意することが解決精度の差となり、情報利得が生まれます。
新しい切り口で情報を再構築する
同じ情報でも切り口が違えば、情報の価値は変化します。検索意図との適合を前提に、独自性のある再構築ができれば、情報利得を生み出すことは可能です。再構築の切り口としては、次のようなものがあるでしょう。
- 意見の違い
- 時系列で並べ替え
- 因果関係の分析
- 新しい軸で比較
- リスクや未来予測の観点
たとえば「〇〇法により副業をする人の割合は5年間で3パーセント増加した」というデータがあったとします。
このデータがもたらす情報の価値も見方次第です。「法改正で3パーセントも上がった。働き方改革が進んでいる」と見ることもできますし「法改正したのに3パーセントしか上がっていない。企業の副業に対する拒否反応は強い」と見ることもできるでしょう。このように、同じ情報でも既存コンテンツとは異なる意見を軸に再構築すれば、それは新規情報として成立します。
検索意図との適合が前提になりますが、切り口を変えた情報の再構築も、情報利得を高める手段です。
まとめ
Googleが求める独自性とは「Web全体に新しい価値を提供すること」です。既存・新規情報に関わらず、ユーザーが他では得られない価値を提供することが前提になります。
情報利得が求められる時代において、SEOは「Web全体にどれだけ新しい価値を提供できるか」というマクロな視点が求められます。 少量でも独自性のある記事が、大量の模倣記事を上回る時代です。持続的なSEO成果を得るために、人間だけが生み出せる独自情報の積み上げに注力しましょう。